Week 8+9+10 @ CircuitVerse
In this blog, I will be writing about my final 3 weeks of GSoC at CircuitVerse and some of the major changes I made in the project.
This is in continuation to my GSoC journey at CircuitVerse that I have documented through blogs. If you have landed here for the first time, I would request you to read the previous blog(preferably all the previous blogs).

As I had mentioned in my previous blog post, the K-Means layer had the following issues:
- More time taken for recommendations
- Uneven distribution of projects
- Item distances couldn’t be used for the 2nd layer since K-Means had a complexity of O(N ² * log (N)) which was heavy computationally.

So we replaced K-Means with K-D Trees and it had the following advantages:
- The time complexity of the nearest neighbor search of K-D Tree is
O(log n)(hence it can be used online). - The cost for building the tree is
O(N log(N))(faster training).
Week 8
Work Completed in week 8:
- K-D Trees implemented on top of LDA.
- Planned and implemented the 2nd layer
- Created testing scripts for new projects and old projects
- Pre-Computed recommendations for the old projects and stored the models
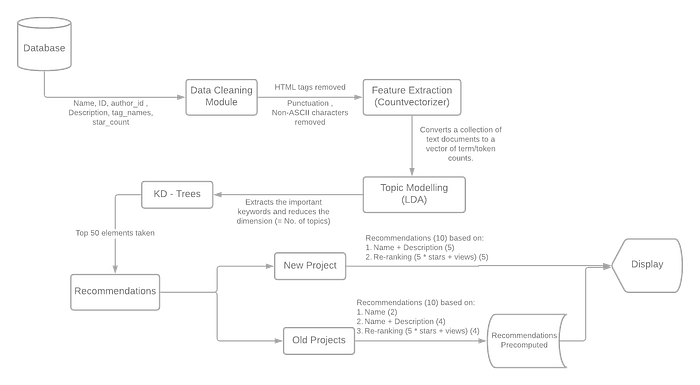
K- D Trees
I was kinda scared since I never had worked with K-D Trees before. Thanks to the simple implementation provided by Sci-Kit Learn, it was not even a full day’s work!
- The time complexity of training reduced by a factor of N (pre-computation became much faster)
- Searching time reduced to O(log N) (hence a distance-based metric could be used for recommending new projects too)
2nd Layer
We wanted to incorporate distance-based recommendations in our 2nd layer to enhance the quality of recommendations (lesser the distance, more similar are the projects) and K-D Trees helped us do that.
The structure of the 2nd layer was as follows:
- The top 5 recommendations would be purely distance-based by simply finding the closest 5 neighbors of the project in the K-D Tree.
- The next 5 recommendations would be re-ranking the remaining 45 neighbors, based on the number of stars and views.
Testing Scripts
Old Projects
The results for the old projects had to be pre-computed and stored so that accessing them can be an O(1) time operation. This was fairly simple, just running the model on the dataset and calculating recommendations, appending them to a list, and finally dumping the list as a JSON file.
New Projects
The process for the new project was exactly similar to old projects (this changed in week 9).
Storing the models
Since the models were now almost final, we stored them using Joblib for both fitted (for new projects ) and fit_transformed values (for old projects).
Week 9
A funny unexpected problem
The results were more amazing than my expectations. However, there was a major problem that we faced this week. Our model was giving really poor recommendations for well — documented circuits, like this one.

And funnily enough, the reason behind the problem was how “well” it was documented.
- The majority of the projects are just a name and some of them had a small description, thus a lesser number of “important” words. This can be proven by the fact that just 10 topics in LDA are able to describe everything about most of the projects and give the best results. Hence for these well-documented circuits, the model was not able to judge which topic does it belong to since it had soo many “important” words.
- The word “SAP” was just used in the name of the project and not even once in the description, so CountVectorizer didn’t find it important enough to be included since it had lesser counts.
Therefore, such well-documented circuits are actually an outliner for the model.
Proposed Solutions
- To just count the description length and recommend such projects with similar description lengths. Basically, a well-documented project would have other well-documented projects as recommendations. They may or may not be remotely close.
- Use the “name” of the project separately without combining it with the description for the first 2 recommendations.
Obviously, we went for the 2nd solution. So for the old projects, the top 2 recommendations were based on just the name, the next 4 based on name + description, and the last 4 re-ranked on the basis of stars and views.
You can check out the difference in recommended projects here.
Seems complicated? Let me add a diagram for the final recommendation system that was ready at the end of week 9!
Runtime of the model
The model runs and prints the recommendations in 1.5 seconds for old projects and around 2 seconds for the new projects.
Pull Requests Made
[#2367] Project files and codes
Week 10
I was super proud that I implemented so much during weeks 8 and 9 and hence my final week 10 is smooth (an important tip for GSoC peeps).
With my project almost over, all I have left is writing 3 blog posts (one for week 6 + 7, this one, and one final project report) and I hope, I pass GSoC with flying colors.
The learning curve has been the steepest but the mentors make sure you don’t slip (hmm, that was pretty smooth). CircuitVerse had the right amount of discipline, management, and freedom when it came to finishing your tasks and that’s what made my experience amazing! I learned so much not just about my project but also from other GSoCers at CircuitVerse. Kudos to the amazing team and the community!
Read my other blogs
If you are new to this series, you can check out my previous blogs and you can also check out my youtube channel and I am sure you’ll learn something new.🎉
Do Follow for more such blogs !
